Overview of LeanDojo
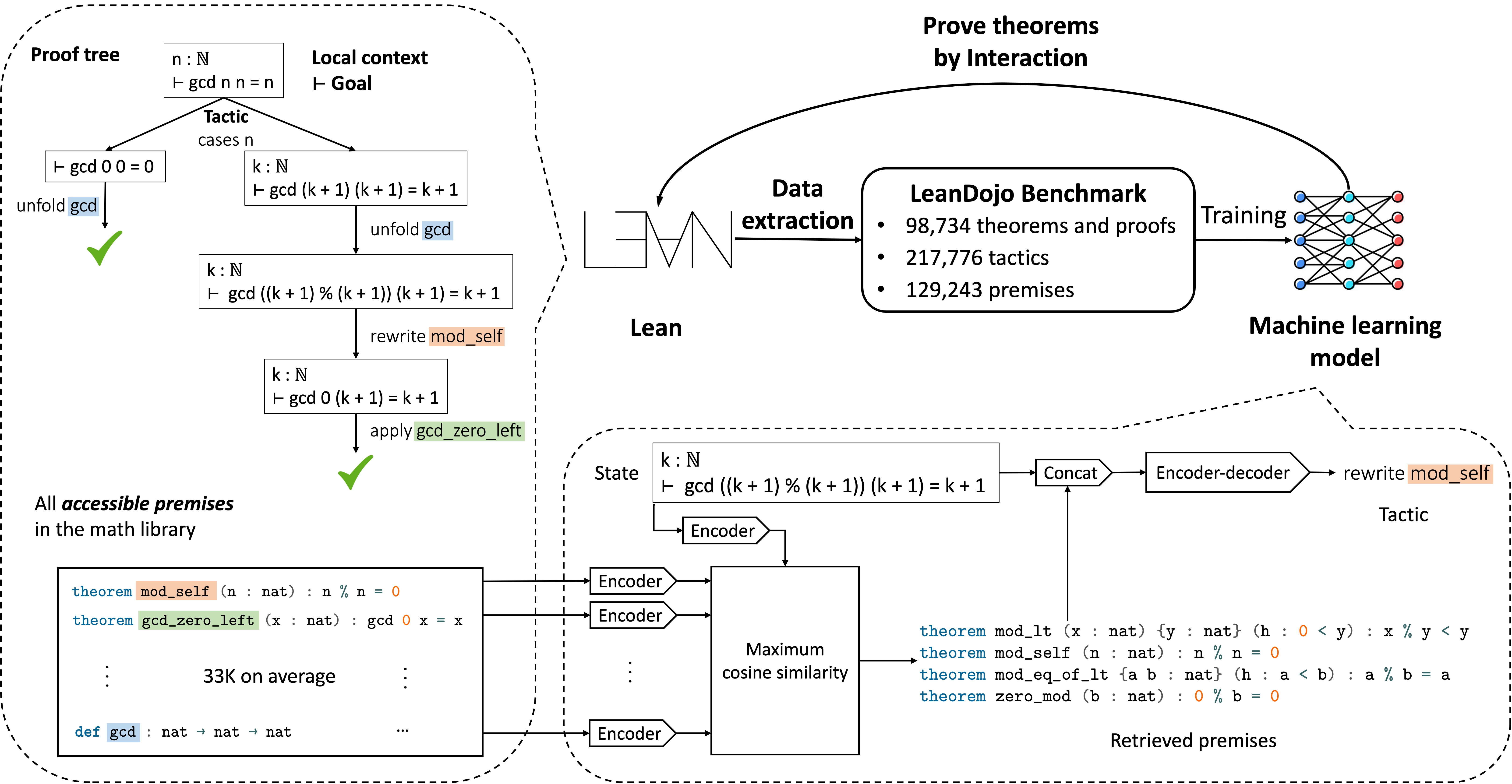
Top right: LeanDojo extracts proofs in Lean into datasets for training machine learning models. It also enables the trained model to prove theorems by interacting with Lean's proof environment.
Top left: The proof tree of a Lean theorem \(\forall n \in \mathbb{N},~\texttt{gcd n n = n}\), where \(\texttt{gcd}\) is the greatest common divisor. When proving the theorem, we start from the original theorem as the initial state (the root) and repeatedly apply tactics (the edges) to decompose states into simpler sub-states, until all states are solved (the leaf nodes). Tactics may rely on premises such as \(\texttt{mod_self}\) and \(\texttt{gcd_zero_left}\) defined in a large math library. E.g., \(\texttt{mod_self}\) is an existing theorem \(\forall n \in \mathbb{N},~\texttt{n % n = 0}\) used in the proof to simplify the goal.
Bottom: Our ReProver model. Given a state, it retrieves premises from the math library, which are concatenated with the state and fed into an encoder-decoder Transformer to generate the next tactic.